Daedalean Tensor Accelerator: Achieving the theoretical maximum speed rating
What was the goal
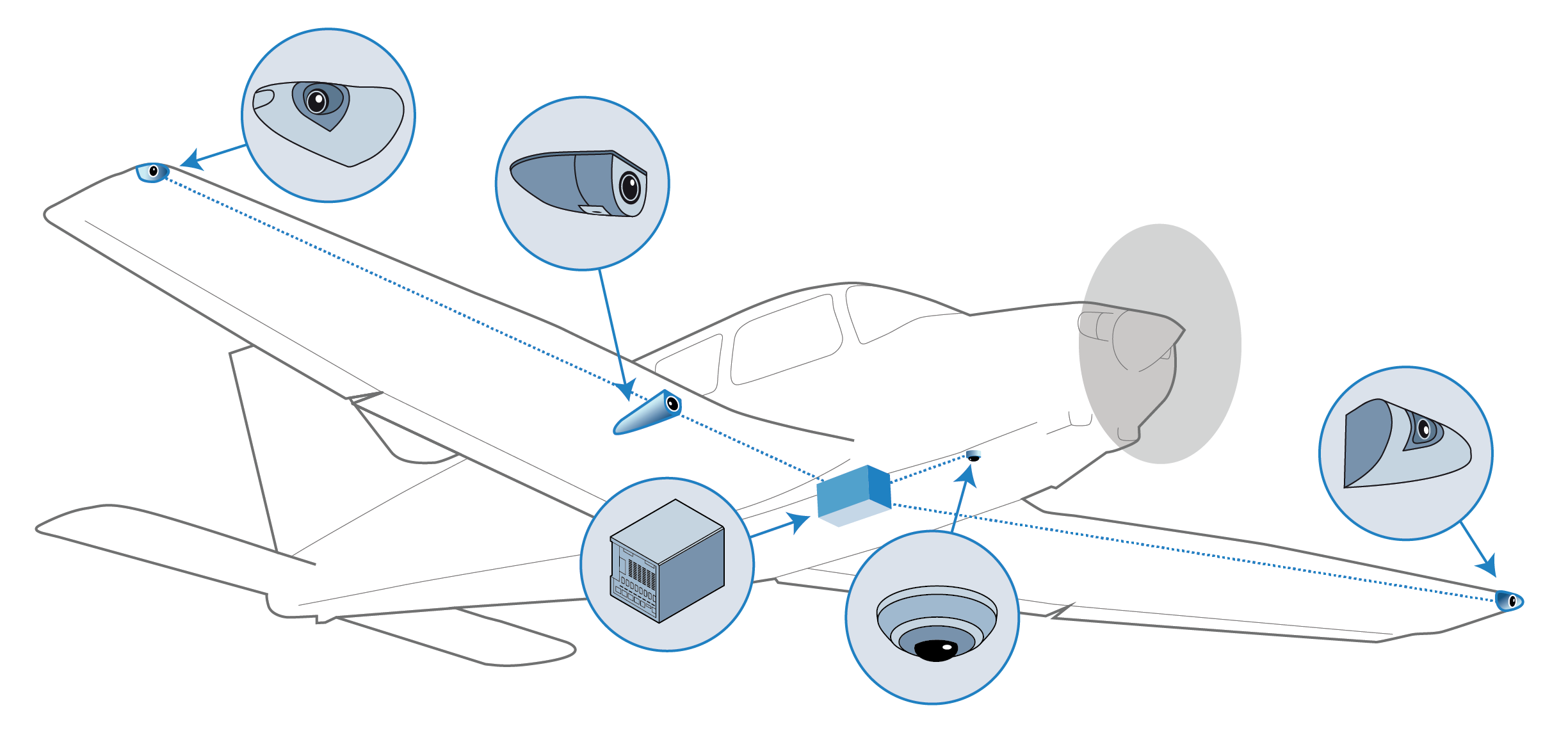
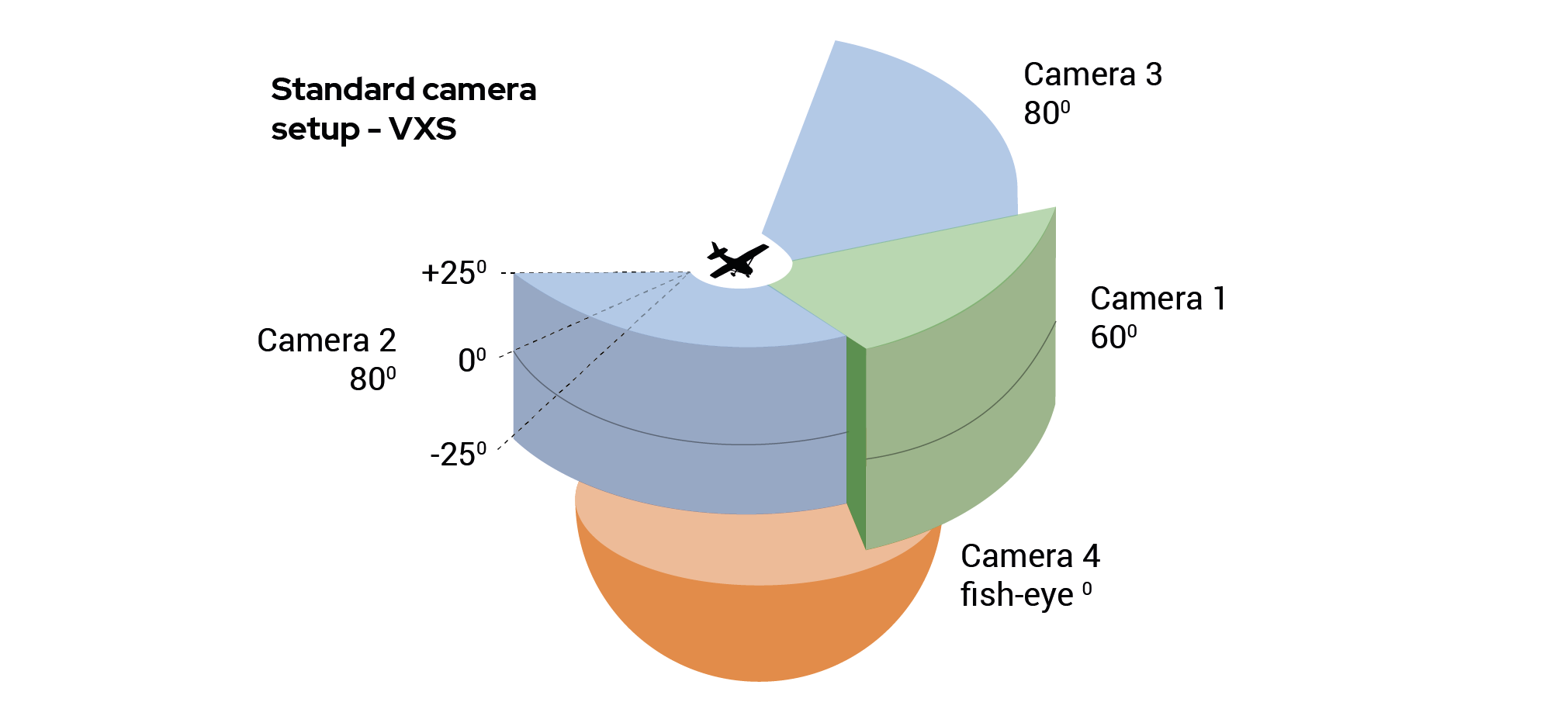

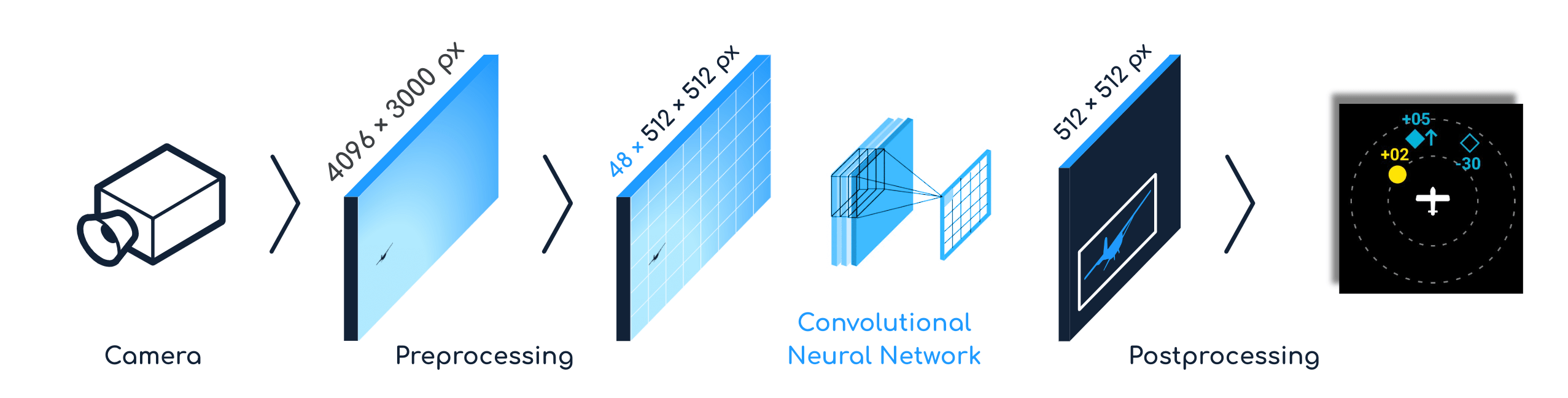
What was the solution
How we achieved 500 MHz for processing 6 fps
- as efficient as possible (do as much work as possible per clock cycle)
- as busy as possible (to do some work at every clock cycle)
- as fast as possible (to do as many clock cycles as possible per second).
First, we needed to make sure that the DSPs were as efficient as possible.
To achieve this, we worked with our neural network architects to optimize the precision of the calculations, such that we can process two data elements in parallel per clock cycle on the built-in multipliers of the FPGA. As a consequence, we effectively double the performance of our compute instructions. (This method is well-known and outlined by Xilinx here.)
Also, to find an optimized solution that maximizes the use of the DSPs, Noam Gallmann and Johannes Frohnhofen have carefully mapped the operations required by the neural network to the capabilities of the DSPs. This work involved analyzing the mathematical operations involved in the neural network and reformulating them to take advantage of the DSP's efficient processing capabilities. Noam and Johannes also carefully examined the interdependencies between different operations and their results to identify opportunities for optimization.

Noam Gallmann
FPGA Design and Verification Engineer at Daedalean. Formerly also worked as Research Assistant at the Institute for Integrated Systems (ETH Zürich), and before that received his MSc in Physics and Programming there.

Johannes Frohnhofen
Software Engineer at Daedalean. Background: Google and Scalable Minds. Received his MSc in IT Systems Engineering at Hasso Plattner Institute, Potsdam.
Finally, we wanted the DSP cores to work as fast as possible. This is where the most work of the Platform team was put in.
Marc Gantenbein and Noam Gallmann oversaw the improvement of the overall architecture of the DTA – optimized the individual compute units, the memory structure, and fetching instructions and data from external memory. This endeavor took lots and lots of minor incremental improvements – writing the code in a way that makes it possible to run at the required speed with as few resources as possible.
Christoph Glattfelder optimized the clocking of the design. As various parts of the FPGA work at different frequencies, the DTA needed to be partitioned into slow and fast regions to help ensure that only the essential parts of the design were optimized.

Christoph Glattfelder
FPGA Design and Verification Engineer at Daedalean. Before that, he worked at Enclustra GmbH and the Institute of Embedded Systems. He got his Dipl. El. Ing. FH (Engineer’s diploma, equivalent to MSc) at the Zürich University of Applied Sciences.

Marc Gantenbein
FPGA Design and Verification engineer working on hardware accelerators for AI on FPGA at Daedalean. He joined us last year after receiving his MSc diploma in Electrical Engineering and IT at ETH Zürich.

Dr. Sota Sawaguchi
ML Hardware Design and Verification Engineer at Daedalean. Formerly, Researcher PhD Student at CEA France (French Alternative Energies and Atomic Energy Commission). After studying at Keio University in Tokyo, he received his PhD in CS at Université Grenoble Alpes.