
After a century of engineering that has seen all systems getting increasingly better over time, we will inevitably end up in a situation where humans are the weakest link. Therefore, if we want to increase the density of airspace use while maintaining at least the same level of safety, humans must be replaced with systems. That is why our goal has been to develop the machine equivalent of human capabilities within this field.

Let’s consider what human pilots actually do in civil aviation today. Their role is quite central. Processes in avionics are deliberately not very integrated – they all go through a set of eyes and a human visual cortex to make the final decision. Maybe, if we could redesign the global civil aviation system from the ground up, we could get a long way in terms of proper system engineering and automation. However, the reality is that human functions are deeply integrated into the whole process, and it is hardly possible to uproot the entire system of rules and regulations.

Thus, to make improvements, we could either introduce more innovative instruments but still require a pilot’s oversight—or, we could consider another approach: determine a uniquely human capability and begin by developing that.In our case, we started by exploring and decomposing the commercial pilot license skill test for helicopter pilots. It provides an excellent roadmap of what actions pilots actually take during a flight. Specifically, a pilot can fly an aircraft from A to B using their vision to see where they are, where they can fly to, where other people are flying that they should not fly into, and where it is safe to land.

When pilots start learning to fly an aircraft, they normally do so according to visual flight rules (VFR) and in visual conditions. This allows them to fly with minimal dependency on air traffic control and other external situations. This is also a great starting point for developing autonomous flight because we can begin to experiment according to simpler setups without the need to integrate air traffic control.So, the first function we have chosen to replicate relates to pilots flying under VFR and visual conditions and using their vision to see where they are. Indeed, the knowledge of your own positioning is fundamental to any form of control—if you do not know where you are, you also would not know how you can get somewhere else.

To reproduce this ability, we have developed a system that, just like a human, can look out the window and reconstruct the position of the aircraft from the motion of the pictures over time. Our system achieves this without relying on GPS or any other GNSS. GPS is a miracle indeed, but humans have flown around reliably without it for almost a century. Moreover, GPS is not available everywhere; the signal can be lost, jammed, or spoofed, and so there should be a backup function for safety reasons.Our camera can be mounted under the aircraft, and the neural network can deduce its own position from how the image changes over time. And, separately, it can also recognise static landmarks, such as some unique skyscrapers that constitute the skyline of a city, certain characteristic mountain tops by their shape, or specific lakes and coastlines. For example, if you fly from San Francisco to LA, you could follow a specific series of mountain ranges and coastlines that would provide points of reference without any need for GPS.The second function for replication relates to a pilot having to use their vision to deconflict with other traffic, including that which may not show up on the radar. Some possible hazards are non-cooperative, meaning they don't try to actively warn us of their presence, for example, by failing to emit ADS-B signals. Moreover, if a pilot flies without guidance from air traffic control, it is their responsibility. Even if the radar is broken, that's not an excuse to fly into things.

By the way, humans are not very effective at this for the simple reason that they can only look in one direction at a given moment. In contrast, a neural network can perceive all megapixels in its image simultaneously, so it doesn’t need to divide its ‘attention’. Another benefit of neural networks is that the most dangerous traffic—the one on a collision course with you—is also the most likely to be missed by human eyes. This is because it does not appear to move, just growing slowly while staying in the same spot.Incidentally, this aspect is also the reason that autonomous flying is much simpler than autonomous driving. A car autopilot has to distinguish between, for example, a rock, a bicycle, another car and a car with a bike rack on the back. Also, pedestrians are unpredictable. In comparison, the sky is nice and empty; if you see something, just do not fly towards it, with a minimal set of exceptions.The third, and arguably the most important, function for replication is finding places to land safely. Those can be either regular landing spaces, such as a runway, or emergency landing spots, where a pilot has to make the call on which is the least undesirable option for landing. However, even in the case of runways, vision is crucial because out of more than 20,000 commercial airports globally, only 228 have a Category 3 ILS infrastructure (source), which guides an aircraft all the way to the ground (provided there is specific expensive equipment onboard). However, human pilots routinely manage to land aircraft safely by just using their eyes.
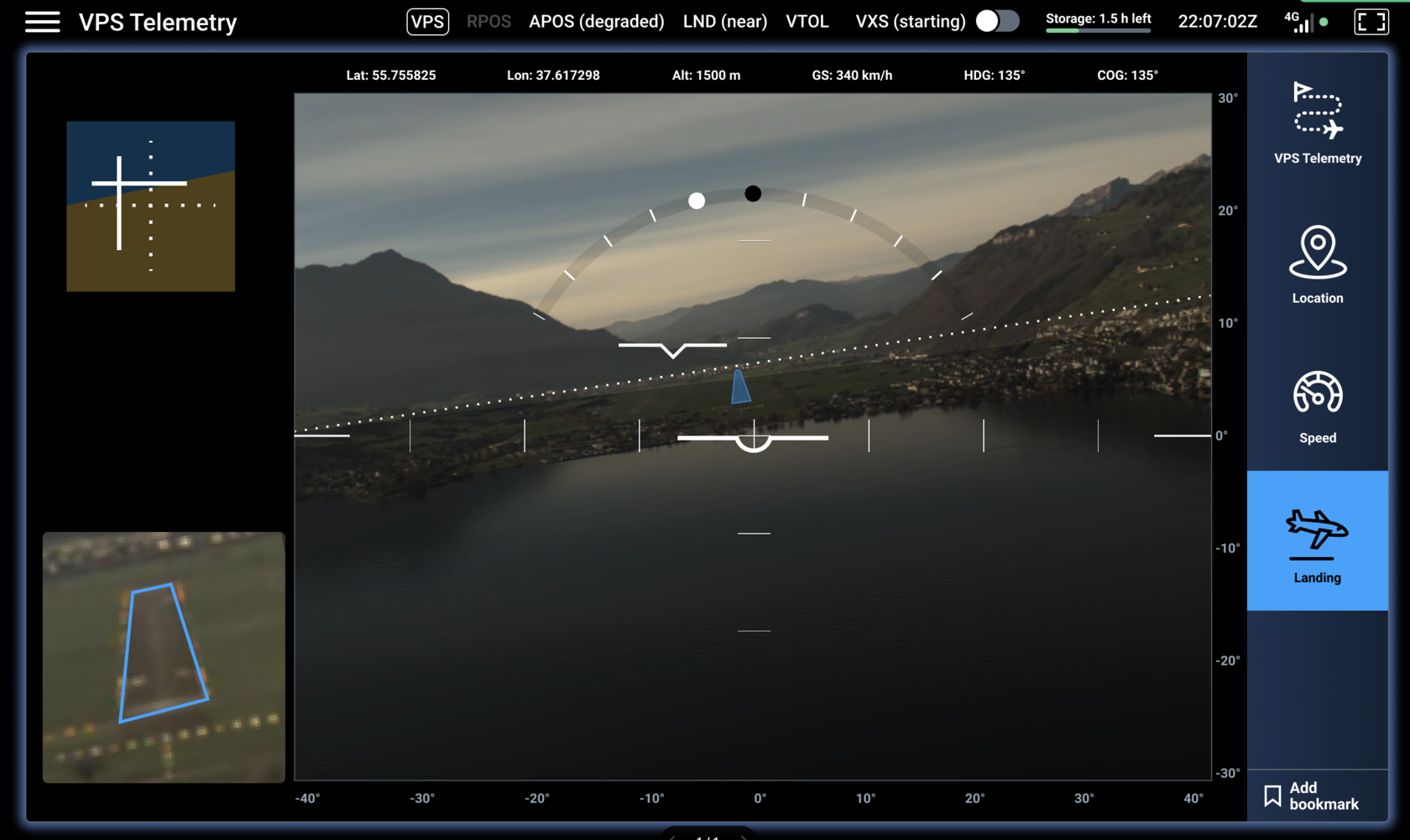
All in all, for pilots, using eyes is fundamental, yet it is something that computers haven’t been able to do very well until fairly recently. The current regulatory framework assumes that there’s always a pilot on board (with eyes and visual cortex). The same tasks will inevitably be an integral part of the final, fully autonomous solution. At the same time, this is the hardest part of the problem; everything else related to flight control was developed decades ago and, since that time, has been working well.But that doesn’t mean we are limited to just using vision. Once we prove that machine-learning-based algorithms can sufficiently solve the tasks named above, there’s no reason that they can’t use the input from other sensors, including, for example, radar and lidar. In fact, this will result in a situation awareness that will go beyond human capabilities. However, this expansion using different sensor modes is just a routine problem after the key issue is cracked, and we aim to deal with the hardest problem first.


-1.jpg)
