


The diagram shows the tightly packed essence of the learning assurance life cycle – the new methodology aiming to build the process of creating a machine learning application to satisfy the strongest requirements. What's inside, and why is it innovative?
Traditional model: V-shape
Let's start with key terminology.
Software assurance is a set of processes aimed at providing guarantees of the intended function, in particular the absence of bugs. These processes are included in the development life cycle, from initial planning to the final testing. They are not costless and not flexible. For the majority of commercial user applications nowadays, the classical software assurance doesn't fit: to be successful, you need to be flexible, address changes and follow the market trends closely – so the alternative iterative and incremental approaches, such as Agile, are more applicable.
But in the fields where software is critical for safety – be it aviation, health care or industrial controlling – you can't cut corners and save time by skipping the "bug-free" requirement during the long design planning stage, as well as all the other procedures. Your priorities differ: safety first.
Verification and validation. These are both parts of software assurance activity – but they are not the same! To avoid confusing them, remember the formula by Barry W. Boehm:
· Verification: Are we building the product right?
· Validation: Are we building the right product?
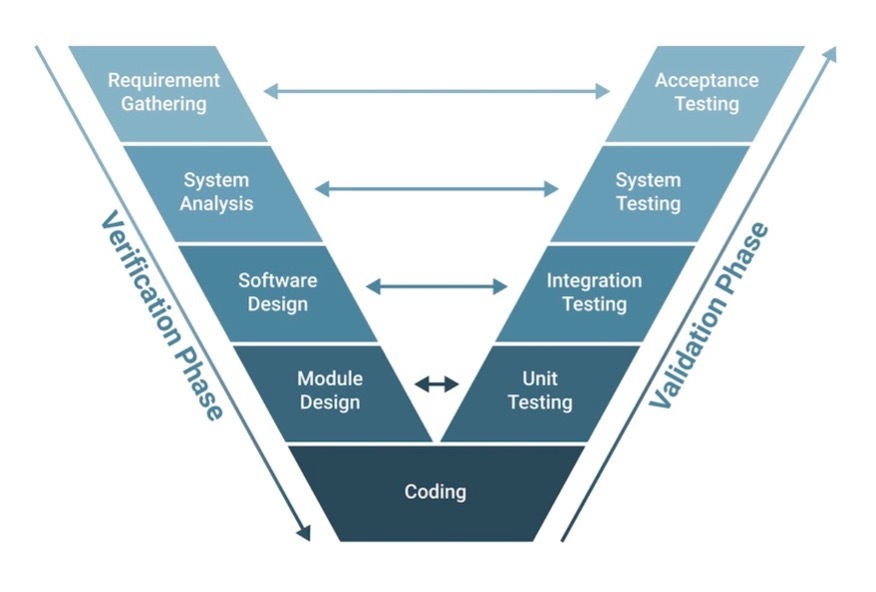
In other words, during verification we check if the product meets the requirements: it has all the features for its intended use, as described at the planning stage after checking with its potential users, and these features work as intended. This implies, first, ascertaining the requirements, then creating the system design specification based on them. Then we go deeper and develop the code specification based, in turn, on the previous step; and deeper again, repeating that for each of the modules of the system.
And during validation, we check if the requirements describe what is really needed – if they correctly address stakeholders' goals and the resulting software fits the intended use. This is done as an internal control (analyzing the requirements, testing the code) and as an external control – through the feedback of the intended users.
Together, they comprise the classic V-shape model of software development:
And now back to machine learning
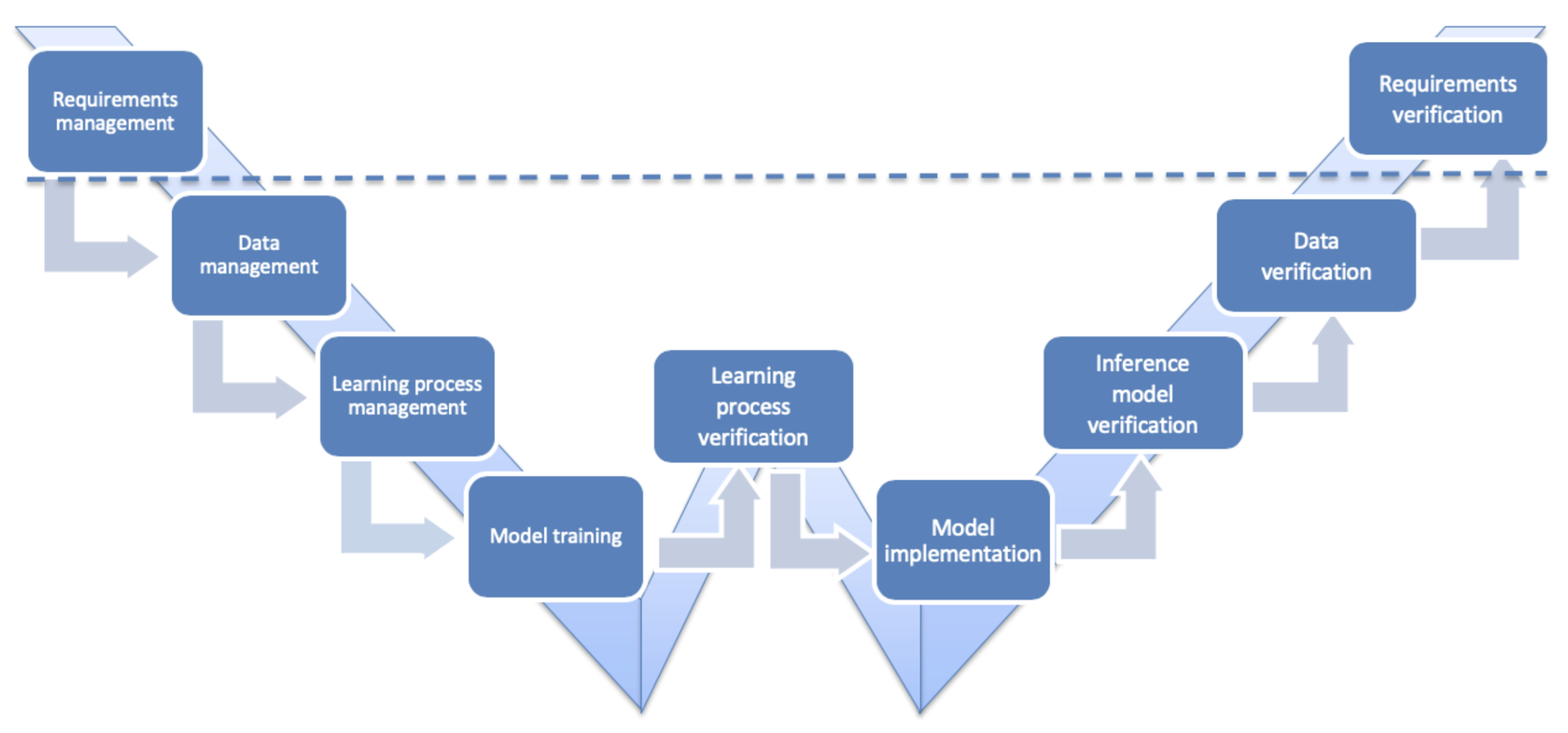
When we create an application based on a neural network (NN), there is still a lot of 'classical' code around NN: tracking, monitoring, and inference. The process described above does apply to it. But the key function of such an application is driven by a machine-learned model, and this classical procedure can't verify it: there are no lines of code or program modules that can be checked line by line. Instead of software assurance, we need to do the learning assurance – and how to conduct this procedure is not yet defined by standards. Neither are there frameworks accepted by regulators for certification purposes. The guidelines published by Daedalean and EASA in Concepts of Design Assurance for Neural Networks (CoDANN) may become a basis for future regulatory requirements. We outlined them by the W-shape. Look at it again:
If we compare it to the classical V-shape above, we notice that everything related to the requirements stays the same: we need to gather, describe and verify them. This part is already covered by the existing standards; that's why it is separated by a dotted line.
What is below the line is a new reality. What should we do to ensure our neural networks work as intended, and what does this depend on?
The answer is as follows: correctly designed data, a correctly designed learning process, a correctly designed model. Each of these three can become a dealbreaker if not done properly, and all three can be verified. Let's see how, while walking down and up the stairs of the W-process.
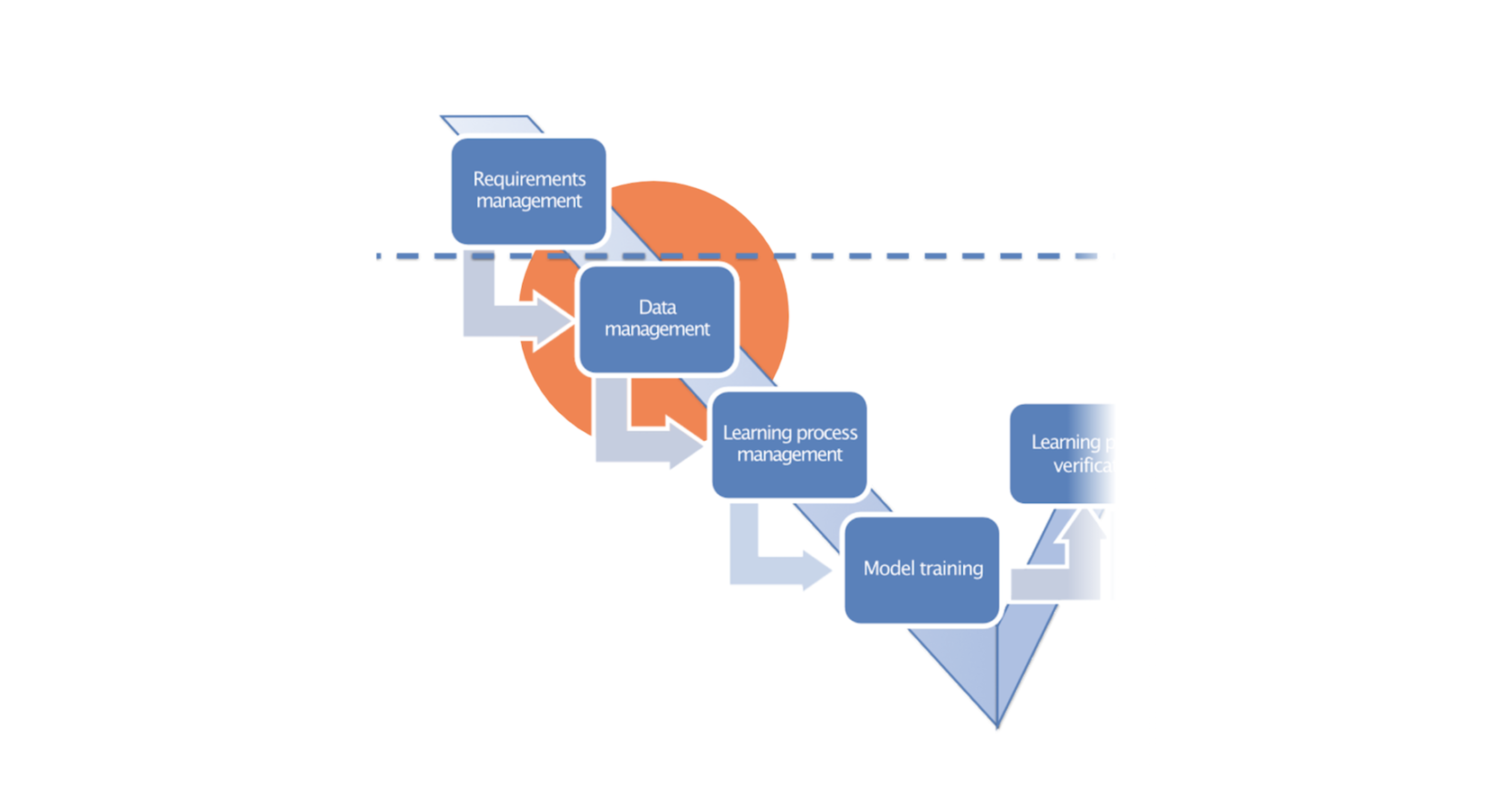
Datasets on which the neural networks will be trained and evaluated. These should correctly represent reality. What does this mean? Here's the list of what could go wrong:
a) Collection and labelling of the data. (See our past blog post on the specifics of data labelling for aviation, including the requirements of traceability of the data).
b) Distribution of the data. We should ensure that there are enough data, that the data are not biased, that their distribution corresponds to the real world, and that they cover all possible cases and scenarios, including the edge – rare – ones.
A brief reminder of what happens when a NN is trained on a poorly designed dataset: the story of Amazon's hiring tool trained on historical data – past resumes and HR decisions taken on them – which developed an anti-woman bias. Nobody checked that the historical data weren't biased in the first place.
Another story explains biased face-recognition tools: a commonly used dataset features content with 74% male faces and 83% white faces. This is a bad dataset for you, not covering less typical cases and resulting in regular scandals with software that doesn't correctly recognize Michelle Obama or Serena Williams.
And back in 2018, IBM had to close their cancer recognition program, which was revealed to provide doctors with bad advice and wrong diagnoses: it had been trained on hypothetical cases written by doctors, not on real patient data. There’s nothing wrong with using synthetic data – if you follow the same assurance rules with them, perform a careful analysis of domain bias and its impact, ensure they correspond to the real data distribution and cover all the input variations. But in the named case, they used a small dataset that reflected the treatment preferences of the particular doctors who designed the hypothetical cases.
Now, when we are sure (and can prove to a certifying regulator) that our training dataset is ideal, there is a new rule not to slip up easily:
c) Independence of the training, validation, and testing datasets. An NN must be evaluated on a different dataset than the one it has been trained on.
From here – down the W-shape: our next step is to design the future learning process. This means choosing appropriate training models and methods: for some tasks, the best result is achieved with unsupervised learning (when we feed an NN with lots of unlabeled data and let it find patterns); for another – the supervised learning (learning on a pre-labelled dataset). This design phase includes, in particular, choosing evaluation metrics that should relate to higher-level requirements.
Here comes the time of the actual training. It is using the data and the learning process defined in the two previous steps. When done; we evaluate the performance using a different, independent dataset. The training means millions of iterations, and at this point, the model architecture can still evolve.
But after this, we verify the model using yet another – testing – dataset. If the results are satisfactory – the values for each metric are correct – then we 'freeze' the model. After that, it becomes deterministic, will not evolve further, and will always produce the same results in the same situation.
Which brings us here:
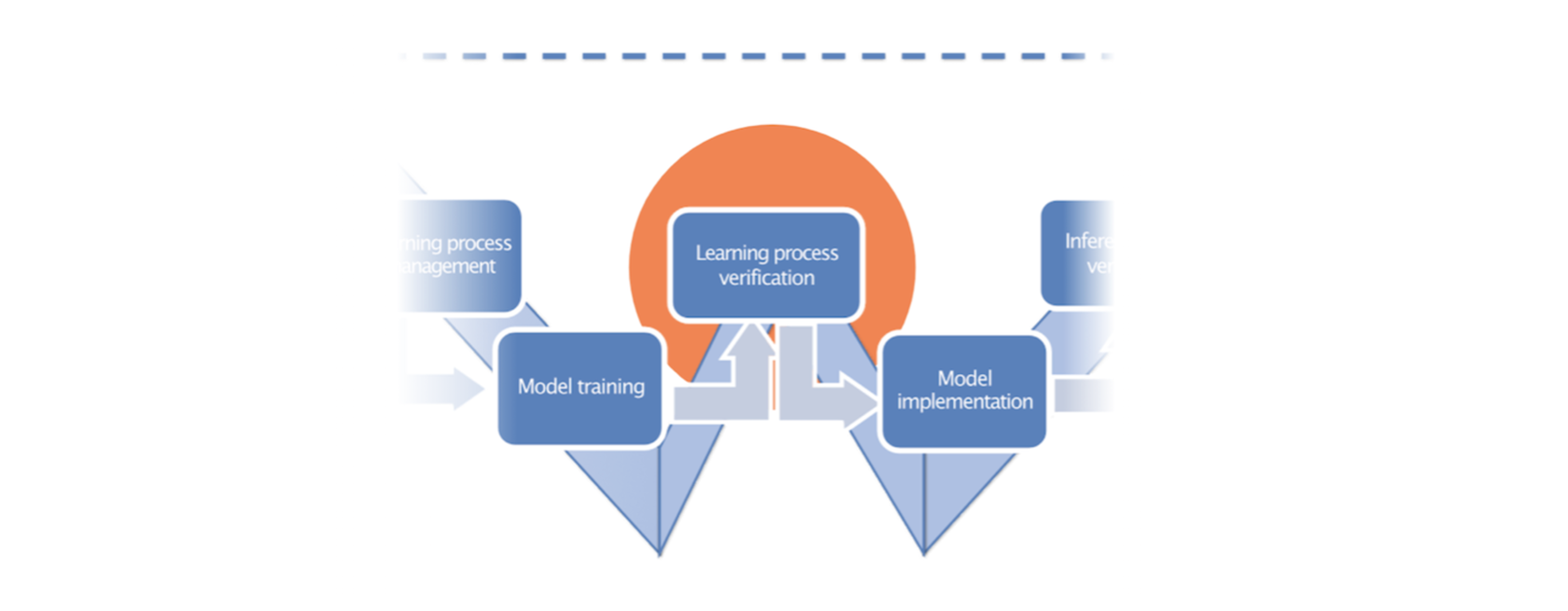
After this point, we implement the model into the actual software used in real operational conditions – in the Daedalean case, this means on real aviation hardware with its limited memory, stack, and computational performance. We need to verify that this software has the same properties as the training model. This is called 'inference model verification’. And subsequently, we go up the stairs of the W: verify that the data have been managed correctly throughout the cycle, are independent and complete – and next, that all the requirements set on the first step have been met.
This is, of course, only high-level guidance, and the detailed standards and thresholds have to be developed further and for each particular use case. But what is essential is that this guidance is universal and industry-agnostic. The W-shape model can be applied to any safety-critical application – not only in aviation – to ensure that neural networks are at least as safe, predictable, and reliable as any existing software.


